Fill in Blanks
Home
1.1 Bivariate Relationships
1.2 Probabilistic Models
1.3 Estimation of the Line
1.4 Properties of the Least Squares Estimators
1.5 Estimation of the Variance
2.1 The Normal Errors Model
2.2 Inferences for the Slope
2.3 Inferences for the Intercept
2.4 Correlation and Coefficient of Determination
2.5 Estimating the Mean Response
2.6 Predicting the Response
3.1 Residual Diagnostics
3.2 The Linearity Assumption
3.3 Homogeneity of Variance
3.4 Checking for Outliers
3.5 Correlated Error Terms
3.6 Normality of the Residuals
4.1 More Than One Predictor Variable
4.2 Estimating the Multiple Regression Model
4.3 A Primer on Matrices
4.4 The Regression Model in Matrix Terms
4.5 Least Squares and Inferences Using Matrices
4.6 ANOVA and Adjusted Coefficient of Determination
4.7 Estimation and Prediction of the Response
5.1 Multicollinearity and Its Effects
5.2 Adding a Predictor Variable
5.3 Outliers and Influential Cases
5.4 Residual Diagnostics
5.5 Remedial Measures
8.1 Logistic Regression
"If all you have is a hammer, everything looks like a nail."
- Bernard Baruch
In a variety of regression applications, the response variable of interest has only two possible
qualitative outcomes, and therefore can be represented by a binary indicator variable taking
on values 0 and 1.
A binary response variable is said to involve binary responses or dichotomous responses.
We consider first the meaning of the response function when the outcome variable is binary, and then we take up some special problems that arise with this type of response variable.
A binary response variable is said to involve binary responses or dichotomous responses.
We consider first the meaning of the response function when the outcome variable is binary, and then we take up some special problems that arise with this type of response variable.
Consider the simple linear regression model
\begin{align*}
Y_{i} & =\beta_{0}+\beta_{1}X_{i}+\varepsilon_{i}\qquad Y_{i}=0,1
\end{align*}
where the outcome $Y_{i}$ is binary taking on the value of either
0 or 1.
The expected response $E\left\{ Y_{i}\right\} $ has a special meaning in this case.
Since $E\left\{ \varepsilon_{i}\right\} =0$, we have \begin{align*} E\left\{ Y_{i}\right\} & =\beta_{0}+\beta_{1}X_{i} \end{align*} Consider $Y_{i}$ to be a Bernoulli random variable for which we can state the probability distribution as follows \begin{align*} Y_{i} & \quad\textbf{ Probability}\\ 1 & \quad P\left(Y_{i}=1\right)=\pi_{i}\\ 0 & \quad P\left(Y_{i}=0\right)=1-\pi_{i} \end{align*} Thus, $\pi_{i}$ is the probability that $Y_{i}=1$ and $1-\pi_{i}$ is the probability that $Y_{i}=0$
By the definition of a random variable, we have \begin{align*} E\left\{ Y_{i}\right\} & =1\left(\pi_{i}\right)+0\left(1-\pi_{i}\right)\\ & =\pi_{i}\\ & =P\left(Y_{i}=1\right) \end{align*} Thus, \begin{align*} E\left\{ Y_{i}\right\} & =\beta_{0}+\beta_{1}X_{i}\\ & =\pi_{i} \end{align*} The mean response $E\{Y_i\}$ as given by the response function is therefore simply the probability that $Y_i = 1$ when the level of the predictor variable is $X_i$.
This interpretation of the mean response applies whether the response function is a simple linear one, as here, or a complex multiple regression one.
The mean response, when the outcome variable is a 0, 1 indicator variable, always represents the probability that $Y = 1$ for the given levels of the predictor variables.
The expected response $E\left\{ Y_{i}\right\} $ has a special meaning in this case.
Since $E\left\{ \varepsilon_{i}\right\} =0$, we have \begin{align*} E\left\{ Y_{i}\right\} & =\beta_{0}+\beta_{1}X_{i} \end{align*} Consider $Y_{i}$ to be a Bernoulli random variable for which we can state the probability distribution as follows \begin{align*} Y_{i} & \quad\textbf{ Probability}\\ 1 & \quad P\left(Y_{i}=1\right)=\pi_{i}\\ 0 & \quad P\left(Y_{i}=0\right)=1-\pi_{i} \end{align*} Thus, $\pi_{i}$ is the probability that $Y_{i}=1$ and $1-\pi_{i}$ is the probability that $Y_{i}=0$
By the definition of a random variable, we have \begin{align*} E\left\{ Y_{i}\right\} & =1\left(\pi_{i}\right)+0\left(1-\pi_{i}\right)\\ & =\pi_{i}\\ & =P\left(Y_{i}=1\right) \end{align*} Thus, \begin{align*} E\left\{ Y_{i}\right\} & =\beta_{0}+\beta_{1}X_{i}\\ & =\pi_{i} \end{align*} The mean response $E\{Y_i\}$ as given by the response function is therefore simply the probability that $Y_i = 1$ when the level of the predictor variable is $X_i$.
This interpretation of the mean response applies whether the response function is a simple linear one, as here, or a complex multiple regression one.
The mean response, when the outcome variable is a 0, 1 indicator variable, always represents the probability that $Y = 1$ for the given levels of the predictor variables.
Special problems arise, unfortunately, when the response variable is an indicator variable.
We consider three of these now, using a simple linear regression model as an illustration.
-
Nonnormal error terms : For a binary 0, 1 response variable, each error term can take on only two values: \begin{align*} \text{When }Y_{i}=1: & \quad\varepsilon_{i}=1-\beta_{0}-\beta_{1}X_{i}\\ \text{When }Y_{i}=0: & \quad\varepsilon_{i}=0-\beta_{0}-\beta_{1}X_{i} \end{align*} Clearly, normal error regression model, which assumes that the $\varepsilon_i$ are normally distributed, is not appropriate. -
Nonconstant Error Variance : Another problem with the error terms is that they do not have equal variances when the response variable is an indicator variable.
To see this, note that \begin{align*} Var\{\varepsilon_i\} = (\beta_{0}+\beta_{1}X_{i})(1-\beta_{0}-\beta_{1}X_{i}) \end{align*} Note that $Var\{\varepsilon_i\}$ depends on $X_i$. Hence, the error variances will differ at different levels of X, and ordinary least squares will no longer be optimal. -
Constraints onResponse Function : Since the response function represents probabilities when the outcome variable is a 0, 1 indicator variable, the mean responses should be constrained as follows: $$ 0\le E\{Y\}=\pi \le 1 $$ The difficulties created by the need for the restriction on the response function are the most serious.
One could use weighted least squares to handle the problem of unequal error variances.
In addition, with large sample sizes the method of least squares provides estimators that are asymptotically normal under quite general conditions, even if the distribution of the error terms is far from normal.
However, the constraint on the mean responses to fall between 0 and 1 frequently will rule out a linear response function.
In this section, we will examine two response functions for modeling binary responses.
These functions are bounded between 0 and 1, have a characteristic sigmoidal- or S-shape, and approach 0 and 1 asymptotically.
These functions arise naturally when the binary response variable results from a zero-one recoding (or dichotomization) of an underlying continuous response variable, and they are often appropriate for discrete binary responses as well.
These functions are bounded between 0 and 1, have a characteristic sigmoidal- or S-shape, and approach 0 and 1 asymptotically.
These functions arise naturally when the binary response variable results from a zero-one recoding (or dichotomization) of an underlying continuous response variable, and they are often appropriate for discrete binary responses as well.
Consider a health researcher studying the effect of a mother's use of alcohol (X -an index
of degree of alcohol use during pregnancy) on the duration of her pregnancy ($Y^C$).
Here we use the superscript $c$ to emphasize that the response variable, pregnancy duration, is a continuous response.
This can be represented by a simple linear regression model: $$ Y^c_i = \beta_0^c+\beta_1^c X_i +\varepsilon_i^c $$ and we will assume that $\varepsilon^c_i$ is normally distributed with mean zero and variance $\sigma^2_c$.
If the continuous response variable, pregnancy duration, were available, we might proceed with the usual simple linear regression analysis. However, in this instance, researchers coded each pregnancy duration as preterm or full term using the following rule: \begin{align*} Y_{i} & =\begin{cases} 1 & \text{ if }Y_{i}^{c}\le38\text{ weeks (preterm)}\\ 0 & \text{ if }Y_{i}^{c}>38\text{ weeks (full term)} \end{cases} \end{align*} It follows then that \begin{align*} P\left(Y_{i}=1\right)=\pi_{i} & =P\left(Y_{i}^{c}\le38\right)\\ & =P\left(\beta_{0}^{c}+\beta_{1}^{c}X_{i}+\varepsilon_{i}^{c}\le38\right)\\ & =P\left(\varepsilon_{i}^{c}\le38-\beta_{0}^{c}-\beta_{1}^{c}X_{i}\right)\\ & =P\left(\frac{\varepsilon_{i}^{c}}{\sigma_{c}}\le\frac{38-\beta_{0}^{c}}{\sigma_{c}}-\frac{\beta_{1}^{c}}{\sigma_{c}}X_{i}\right)\\ & =P\left(Z\le\beta_{0}^{*}+\beta_{1}^{*}X_{i}\right) \end{align*} where \begin{align*} \beta_{0}^{c} & =\frac{38-\beta_{0}^{c}}{\sigma_{c}}\\ \beta_{1}^{c} & =-\frac{\beta_{1}^{c}}{\sigma_{c}}\\ Z & =\frac{\varepsilon_{i}^{c}}{\sigma_{c}}. \end{align*} Note that $Z$ follows a standard normal distribution.
If we let $P\left(Z\le z\right)=\Phi\left(z\right)$, we have \begin{align*} P\left(Y_{i}=1\right) & =\Phi\left(\beta_{0}^{*}+\beta_{1}^{*}X_{i}\right) \end{align*} From this we have what is known as the probit mean response function \begin{align*} E\left\{ Y_{i}\right\} & =\pi_{i}=\Phi\left(\beta_{0}^{*}+\beta_{1}^{*}X_{i}\right) \end{align*} The inverse function $\Phi^{-1}$ of the standard normal cumulative distribution function is sometimes called theprobit transformation .
We solve for the linear predictor $\beta_{0}^{*}+\beta_{1}^{*}X_{i}$ by applying the probit transformation to both sides of the expression: \begin{align*} \Phi^{-1}\left(\pi_{i}\right) & =\pi_{i}^{\prime}=\beta_{0}^{*}+\beta_{1}^{*}X_{i} \end{align*}
The resulting expression $\pi_{i}^{\prime}=\beta_{0}^{*}+\beta_{1}^{*}X_{i}$ is called the probit response function, or more generally, the linear predictor.
Here we use the superscript $c$ to emphasize that the response variable, pregnancy duration, is a continuous response.
This can be represented by a simple linear regression model: $$ Y^c_i = \beta_0^c+\beta_1^c X_i +\varepsilon_i^c $$ and we will assume that $\varepsilon^c_i$ is normally distributed with mean zero and variance $\sigma^2_c$.
If the continuous response variable, pregnancy duration, were available, we might proceed with the usual simple linear regression analysis. However, in this instance, researchers coded each pregnancy duration as preterm or full term using the following rule: \begin{align*} Y_{i} & =\begin{cases} 1 & \text{ if }Y_{i}^{c}\le38\text{ weeks (preterm)}\\ 0 & \text{ if }Y_{i}^{c}>38\text{ weeks (full term)} \end{cases} \end{align*} It follows then that \begin{align*} P\left(Y_{i}=1\right)=\pi_{i} & =P\left(Y_{i}^{c}\le38\right)\\ & =P\left(\beta_{0}^{c}+\beta_{1}^{c}X_{i}+\varepsilon_{i}^{c}\le38\right)\\ & =P\left(\varepsilon_{i}^{c}\le38-\beta_{0}^{c}-\beta_{1}^{c}X_{i}\right)\\ & =P\left(\frac{\varepsilon_{i}^{c}}{\sigma_{c}}\le\frac{38-\beta_{0}^{c}}{\sigma_{c}}-\frac{\beta_{1}^{c}}{\sigma_{c}}X_{i}\right)\\ & =P\left(Z\le\beta_{0}^{*}+\beta_{1}^{*}X_{i}\right) \end{align*} where \begin{align*} \beta_{0}^{c} & =\frac{38-\beta_{0}^{c}}{\sigma_{c}}\\ \beta_{1}^{c} & =-\frac{\beta_{1}^{c}}{\sigma_{c}}\\ Z & =\frac{\varepsilon_{i}^{c}}{\sigma_{c}}. \end{align*} Note that $Z$ follows a standard normal distribution.
If we let $P\left(Z\le z\right)=\Phi\left(z\right)$, we have \begin{align*} P\left(Y_{i}=1\right) & =\Phi\left(\beta_{0}^{*}+\beta_{1}^{*}X_{i}\right) \end{align*} From this we have what is known as the probit mean response function \begin{align*} E\left\{ Y_{i}\right\} & =\pi_{i}=\Phi\left(\beta_{0}^{*}+\beta_{1}^{*}X_{i}\right) \end{align*} The inverse function $\Phi^{-1}$ of the standard normal cumulative distribution function is sometimes called the
We solve for the linear predictor $\beta_{0}^{*}+\beta_{1}^{*}X_{i}$ by applying the probit transformation to both sides of the expression: \begin{align*} \Phi^{-1}\left(\pi_{i}\right) & =\pi_{i}^{\prime}=\beta_{0}^{*}+\beta_{1}^{*}X_{i} \end{align*}
The resulting expression $\pi_{i}^{\prime}=\beta_{0}^{*}+\beta_{1}^{*}X_{i}$ is called the probit response function, or more generally, the linear predictor.
black line: $\beta_1^*=5$
red line: $\beta_1^*=1$
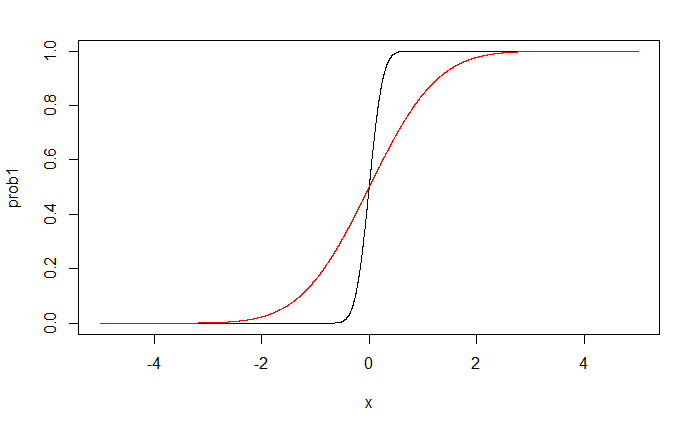
red line: $\beta_1^*=1$
black line: $\beta_0^*=0$
red line: $\beta_0^*=5$
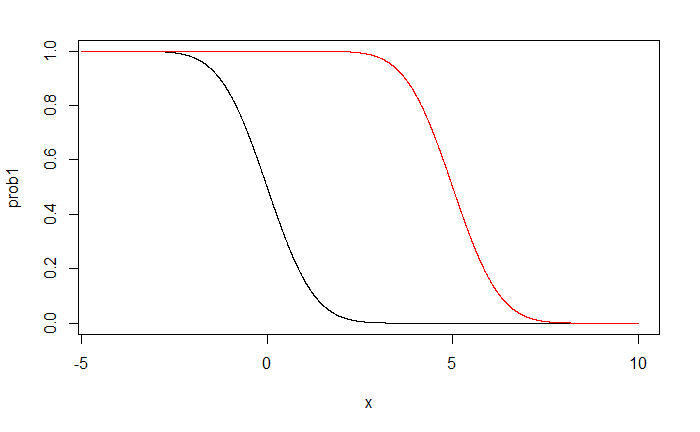
red line: $\beta_0^*=5$
We have seen that the assumption of normally distributed errors for the underlying continuous
response variable led to the use of the standard normal cumulative distribution
function, $\Phi$ to model $\pi_i$.
An alternative error distribution that is very similar to the normal distribution is thelogistic distribution.
Plots of the standard normal density function and the logistic density function, each with mean zero and variance one are nearly indistinguishable, although the logistic distribution has slightly heavier tails.
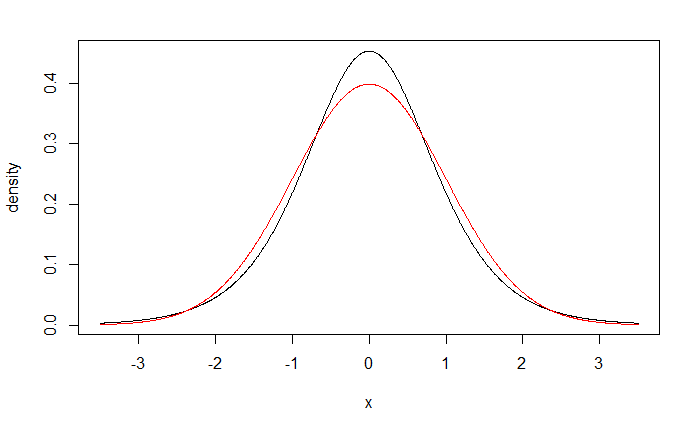
Note the cumulative distribution function of a logistic random variable $\varepsilon_{L}$ having mean 0 and standard deviation $\sigma=\pi/\sqrt{3}$ is: \begin{align*} F_{L}\left(\varepsilon_{L}\right) & =\frac{\exp\left(\varepsilon_{L}\right)}{1+\exp\left(\varepsilon_{L}\right)} \end{align*} Suppose now that $\varepsilon_{i}^{c}$ has a logistic distribution with mean 0 and standard deviation $\sigma_{c}$. Then we have \begin{align*} P\left(Y_{i}=1\right) & =P\left(\frac{\varepsilon_{i}^{c}}{\sigma_{c}}\le\beta_{0}^{*}+\beta_{1}^{*}X_{1}\right) \end{align*} where $\varepsilon_{i}^{c}/\sigma_{c}$ follows a logistic distribution with mean zero and standard deviation one.
Multiplying both sides of the inequality inside the probability statement on the right by $\pi/\sqrt{3}$ gives us \begin{align*} P\left(Y_{i}=1\right)=\pi_{i} & =P\left(\frac{\pi}{\sqrt{3}}\frac{\varepsilon_{i}^{c}}{\sigma_{c}}\le\frac{\pi}{\sqrt{3}}\beta_{0}^{*}+\frac{\pi}{\sqrt{3}}\beta_{1}^{*}X_{i}\right)\\ & =P\left(\varepsilon_{L}\le\beta_{0}+\beta_{1}X_{i}\right)\\ & =F_{L}\left(\beta_{0}+\beta_{1}X_{i}\right)\\ & =\frac{\exp\left(\beta_{0}+\beta_{1}X_{i}\right)}{1+\exp\left(\beta_{0}+\beta_{1}X_{i}\right)} \end{align*} where \begin{align*} \beta_{0} & =\frac{\pi}{\sqrt{3}}\beta_{0}^{*}\\ \beta_{1} & =\frac{\pi}{\sqrt{3}}\beta_{1}^{*} \end{align*} denote the logistic regression parameters.
To summarize, the logistic mean response function is \begin{align*} E\left\{ Y_{i}\right\} & =\pi_{i}\\ & =F_{L}\left(\beta_{0}+\beta_{1}X_{i}\right)\\ & =\frac{\exp\left(\beta_{0}+\beta_{1}X_{i}\right)}{1+\exp\left(\beta_{0}+\beta_{1}X_{i}\right)}\\ & =\frac{1}{1+\exp\left(-\beta_{0}-\beta_{1}X_{i}\right)} \end{align*} Applying the inverse of the cumulative distribution function $F_{L}$ gives \begin{align*} F_{L}^{-1}\left(\pi_{i}\right) & =\beta_{0}+\beta_{1}X_{1}=\pi_{i}^{\prime} \end{align*} $F_{L}^{-1}\left(\pi_{i}\right)$ is called thelogit transformation
and is given by
\begin{align*}
F_{L}^{-1}\left(\pi_{i}\right) & =\log\left(\frac{\pi_{i}}{1-\pi_{i}}\right)
\end{align*}
where the ratio $\pi_{i}/\left(1-\pi_{i}\right)$ is called the odds ratio .
An alternative error distribution that is very similar to the normal distribution is the
Plots of the standard normal density function and the logistic density function, each with mean zero and variance one are nearly indistinguishable, although the logistic distribution has slightly heavier tails.
Note the cumulative distribution function of a logistic random variable $\varepsilon_{L}$ having mean 0 and standard deviation $\sigma=\pi/\sqrt{3}$ is: \begin{align*} F_{L}\left(\varepsilon_{L}\right) & =\frac{\exp\left(\varepsilon_{L}\right)}{1+\exp\left(\varepsilon_{L}\right)} \end{align*} Suppose now that $\varepsilon_{i}^{c}$ has a logistic distribution with mean 0 and standard deviation $\sigma_{c}$. Then we have \begin{align*} P\left(Y_{i}=1\right) & =P\left(\frac{\varepsilon_{i}^{c}}{\sigma_{c}}\le\beta_{0}^{*}+\beta_{1}^{*}X_{1}\right) \end{align*} where $\varepsilon_{i}^{c}/\sigma_{c}$ follows a logistic distribution with mean zero and standard deviation one.
Multiplying both sides of the inequality inside the probability statement on the right by $\pi/\sqrt{3}$ gives us \begin{align*} P\left(Y_{i}=1\right)=\pi_{i} & =P\left(\frac{\pi}{\sqrt{3}}\frac{\varepsilon_{i}^{c}}{\sigma_{c}}\le\frac{\pi}{\sqrt{3}}\beta_{0}^{*}+\frac{\pi}{\sqrt{3}}\beta_{1}^{*}X_{i}\right)\\ & =P\left(\varepsilon_{L}\le\beta_{0}+\beta_{1}X_{i}\right)\\ & =F_{L}\left(\beta_{0}+\beta_{1}X_{i}\right)\\ & =\frac{\exp\left(\beta_{0}+\beta_{1}X_{i}\right)}{1+\exp\left(\beta_{0}+\beta_{1}X_{i}\right)} \end{align*} where \begin{align*} \beta_{0} & =\frac{\pi}{\sqrt{3}}\beta_{0}^{*}\\ \beta_{1} & =\frac{\pi}{\sqrt{3}}\beta_{1}^{*} \end{align*} denote the logistic regression parameters.
To summarize, the logistic mean response function is \begin{align*} E\left\{ Y_{i}\right\} & =\pi_{i}\\ & =F_{L}\left(\beta_{0}+\beta_{1}X_{i}\right)\\ & =\frac{\exp\left(\beta_{0}+\beta_{1}X_{i}\right)}{1+\exp\left(\beta_{0}+\beta_{1}X_{i}\right)}\\ & =\frac{1}{1+\exp\left(-\beta_{0}-\beta_{1}X_{i}\right)} \end{align*} Applying the inverse of the cumulative distribution function $F_{L}$ gives \begin{align*} F_{L}^{-1}\left(\pi_{i}\right) & =\beta_{0}+\beta_{1}X_{1}=\pi_{i}^{\prime} \end{align*} $F_{L}^{-1}\left(\pi_{i}\right)$ is called the
black line: $\beta_1^*=5$
red line: $\beta_1^*=1$
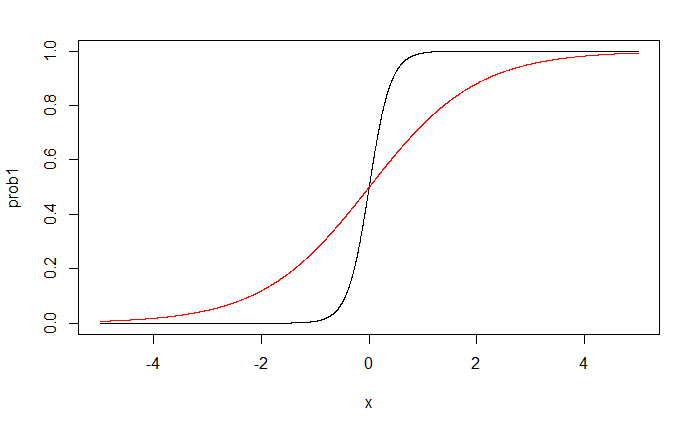
red line: $\beta_1^*=1$
black line: $\beta_0^*=0$
red line: $\beta_0^*=5$
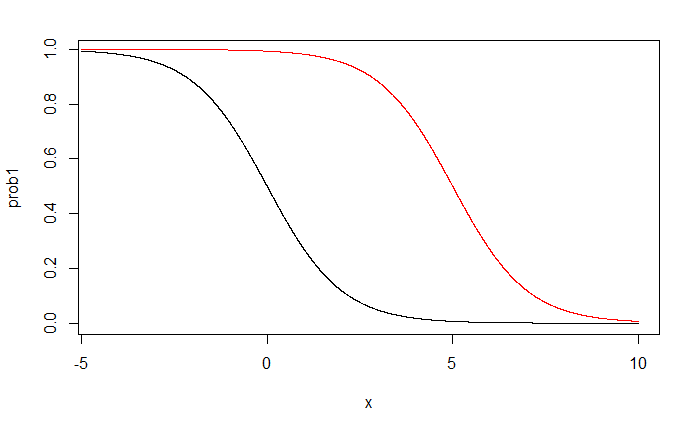
red line: $\beta_0^*=5$
The interpretation of the estimated regression coefficient $b_1$ in the fitted logistic response
function is not the straightforward interpretation of the slope in a linear regression
model.
The reason is that the effect of a unit increase in X varies for the logistic regression model according to the location of the starting point on the X scale.
An interpretation of $b_1$ is found in the property of the fitted logistic function that the estimated odds $$ \frac{\hat{\pi}}{1-\hat{\pi}} $$ are multiplied by $$ \exp(b_1) $$ for any unit increase in X.
To see this, we consider the value of the fitted logit response function at $X = X_j$; $$ \hat{\pi}^\prime (X_j)=b_0+b_1 X_j $$ The notation $\hat{\pi}^\prime (X_j)$ indicates specifically the X level associated with the fitted value.
We also consider the value of the fitted logit response function at $X = X_j + 1$; $$ \hat{\pi}^\prime (X_j+1)=b_0+b_1( X_j+1) $$ The difference between the two fitted values is simply \begin{align*} \hat{\pi}^\prime (X_j+1)-\hat{\pi}^\prime (X_j)& = b_0+b_1( X_j+1) - b_0-b_1 X_j \\ & = b_1 \end{align*} Now $\hat{\pi}^\prime (X_j)$ is the logarithm of the estimated odds when $X=X_j$; we shall denote it by $\ln(\text{odds}_1)$.
Similarly, $\hat{\pi}^\prime (X_j+1)$ is the logarithm of the estimated odds when $X=X_j+1$; we shall denote it by $\ln(\text{odds}_2)$.
Hence, the difference between the two fitted logit response values can be expressed as follows: \begin{align*} \ln(\text{odds}_2)-\ln(\text{odds}_1) = \ln\left(\frac{\text{odds}_2}{\text{odds}_1}\right) = b_1 \end{align*} Taking antilogs (exponentials) of each side, we see that the estimated ratio of the odds, called the odds ratio, $\hat{OR}$, is $$ \hat{OR} = \frac{\text{odds}_2}{\text{odds}_1}=\exp(b_1) $$
The reason is that the effect of a unit increase in X varies for the logistic regression model according to the location of the starting point on the X scale.
An interpretation of $b_1$ is found in the property of the fitted logistic function that the estimated odds $$ \frac{\hat{\pi}}{1-\hat{\pi}} $$ are multiplied by $$ \exp(b_1) $$ for any unit increase in X.
To see this, we consider the value of the fitted logit response function at $X = X_j$; $$ \hat{\pi}^\prime (X_j)=b_0+b_1 X_j $$ The notation $\hat{\pi}^\prime (X_j)$ indicates specifically the X level associated with the fitted value.
We also consider the value of the fitted logit response function at $X = X_j + 1$; $$ \hat{\pi}^\prime (X_j+1)=b_0+b_1( X_j+1) $$ The difference between the two fitted values is simply \begin{align*} \hat{\pi}^\prime (X_j+1)-\hat{\pi}^\prime (X_j)& = b_0+b_1( X_j+1) - b_0-b_1 X_j \\ & = b_1 \end{align*} Now $\hat{\pi}^\prime (X_j)$ is the logarithm of the estimated odds when $X=X_j$; we shall denote it by $\ln(\text{odds}_1)$.
Similarly, $\hat{\pi}^\prime (X_j+1)$ is the logarithm of the estimated odds when $X=X_j+1$; we shall denote it by $\ln(\text{odds}_2)$.
Hence, the difference between the two fitted logit response values can be expressed as follows: \begin{align*} \ln(\text{odds}_2)-\ln(\text{odds}_1) = \ln\left(\frac{\text{odds}_2}{\text{odds}_1}\right) = b_1 \end{align*} Taking antilogs (exponentials) of each side, we see that the estimated ratio of the odds, called the odds ratio, $\hat{OR}$, is $$ \hat{OR} = \frac{\text{odds}_2}{\text{odds}_1}=\exp(b_1) $$
The simple logistic regression model is easily extended to more than one predictor
variable.
In fact, several predictor variables are usually required with logistic regression to obtain adequate description and useful predictions.
In matrix notation, the logistic response function becomes $$ E\{Y\} = \frac{\exp{\left(\textbf{X}^\prime\boldsymbol{\beta}\right)}}{1+\exp{\left(\textbf{X}^\prime\boldsymbol{\beta}\right)}} $$ Like the simple logistic response function, the multiple logistic-response function is monotonic and sigmoidal in shape with respect to $\textbf{X}^\prime\boldsymbol{\beta}$ and is almost linear when $\pi$ is between .2 and .8.
The X variables may be different predictor variables, or some may represent curvature and/or interaction effects.
Also, the predictor variables may be quantitative, or they may be qualitative and represented by indicator variables.
This flexibility makes the multiple logistic regression model very attractive.
In fact, several predictor variables are usually required with logistic regression to obtain adequate description and useful predictions.
In matrix notation, the logistic response function becomes $$ E\{Y\} = \frac{\exp{\left(\textbf{X}^\prime\boldsymbol{\beta}\right)}}{1+\exp{\left(\textbf{X}^\prime\boldsymbol{\beta}\right)}} $$ Like the simple logistic response function, the multiple logistic-response function is monotonic and sigmoidal in shape with respect to $\textbf{X}^\prime\boldsymbol{\beta}$ and is almost linear when $\pi$ is between .2 and .8.
The X variables may be different predictor variables, or some may represent curvature and/or interaction effects.
Also, the predictor variables may be quantitative, or they may be qualitative and represented by indicator variables.
This flexibility makes the multiple logistic regression model very attractive.
In a health study to investigate an epidemic outbreak of a disease that is spread by mosquitoes,
individuals were randomly sampled within two sectors in a city to determine if the person
had recently contracted the disease under study.
This was ascertained by the interviewer, who asked pertinent questions to assess whether certain specific symptoms associated with the disease were present during the specified period.
The response variable Y was coded 1 if this disease was determined to have been present, and 0 if not.
Three predictor variables were included in the study, representing known or potential risk factors.
They are age, socioeconomic status of household, and sector within city.
Age ($X_1$) is a quantitative variable. Socioeconomic status is a categorical variable with three levels. It is represented by two indicator variables ($X_2$ and $X_3$), as follows: \begin{align*} Class &\quad X_1 & X_2\\ Upper & \quad 0 & 0\\ Middle & \quad 1 & 0\\ Lower & \quad 0 & 1 \end{align*} City sector is also a categorical variable. Since there were only two sectors in the study, one indicator variable ($X_4$ ) was used, defined so that $X_4 = 0$ for sector 1 and $X_4 = 1$ for sector 2.
This was ascertained by the interviewer, who asked pertinent questions to assess whether certain specific symptoms associated with the disease were present during the specified period.
The response variable Y was coded 1 if this disease was determined to have been present, and 0 if not.
Three predictor variables were included in the study, representing known or potential risk factors.
They are age, socioeconomic status of household, and sector within city.
Age ($X_1$) is a quantitative variable. Socioeconomic status is a categorical variable with three levels. It is represented by two indicator variables ($X_2$ and $X_3$), as follows: \begin{align*} Class &\quad X_1 & X_2\\ Upper & \quad 0 & 0\\ Middle & \quad 1 & 0\\ Lower & \quad 0 & 1 \end{align*} City sector is also a categorical variable. Since there were only two sectors in the study, one indicator variable ($X_4$ ) was used, defined so that $X_4 = 0$ for sector 1 and $X_4 = 1$ for sector 2.
library(boot)
dat = read.table("http://users.stat.ufl.edu/~rrandles/sta4210/Rclassnotes/
data/textdatasets/KutnerData/Chapter%2014%20Data%20Sets/CH14TA03.txt")
names(dat) = c("id", "X1", "X2", "X3", "X4", "Y")
#fit a logistic regression model using glm
fit = glm(Y~.-id, data=dat,family = binomial(link="logit"))
pred.prob = fit %>% fitted.values()
link = predict(fit, type="link")
plot(link, pred.prob, col= dat$Y+1)
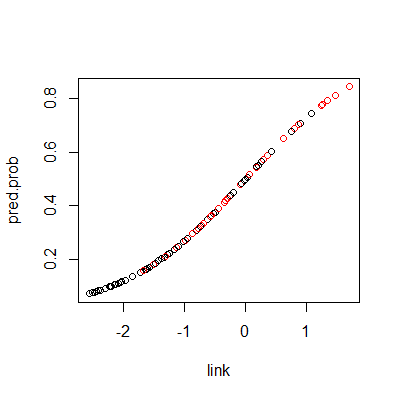 #if we pedict probabilitys greater than .5 as predicting a
#success (predict Y=1), then we can predict the outcomes as
pred.y = ifelse(pred.prob >=.5, "Y","N")
table(pred.y, dat$Y)
#if we pedict probabilitys greater than .5 as predicting a
#success (predict Y=1), then we can predict the outcomes as
pred.y = ifelse(pred.prob >=.5, "Y","N")
table(pred.y, dat$Y)
pred.y 0 1
N 58 19
Y 9 12
summary(fit)
Call:
glm(formula = Y ~ . - id, family = binomial(link = "logit"),
data = dat)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.6552 -0.7529 -0.4788 0.8558 2.0977
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -2.31293 0.64259 -3.599 0.000319 ***
X1 0.02975 0.01350 2.203 0.027577 *
X2 0.40879 0.59900 0.682 0.494954
X3 -0.30525 0.60413 -0.505 0.613362
X4 1.57475 0.50162 3.139 0.001693 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 122.32 on 97 degrees of freedom
Residual deviance: 101.05 on 93 degrees of freedom
AIC: 111.05
Number of Fisher Scoring iterations: 4
fit %>% coef() %>% exp()
(Intercept) X1 X2 X3 X4
0.09897037 1.03019705 1.50499600 0.73693576 4.82953038
cv = cv.glm(dat, fit)
cv$delta
[1] 0.1962685 0.1961593
#compare with probit
#fit a logistic regression model using glm
fit = glm(Y~.-id, data=dat,family = binomial(link="probit"))
pred.prob = fit %>% fitted.values()
link = predict(fit, type="link")
plot(link, pred.prob, col= dat$Y+1)
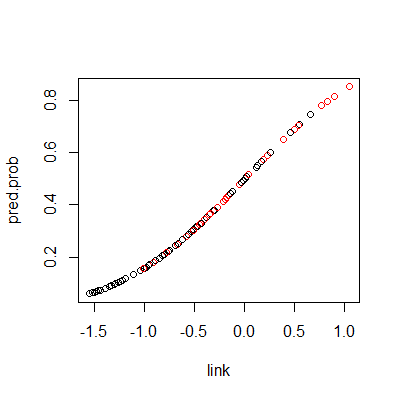 pred.y = ifelse(pred.prob >=.5, "Y","N")
table(pred.y, dat$Y)
pred.y = ifelse(pred.prob >=.5, "Y","N")
table(pred.y, dat$Y)
pred.y 0 1
N 57 19
Y 10 12
cv = cv.glm(dat, fit)
cv$delta
[1] 0.1949919 0.1948840